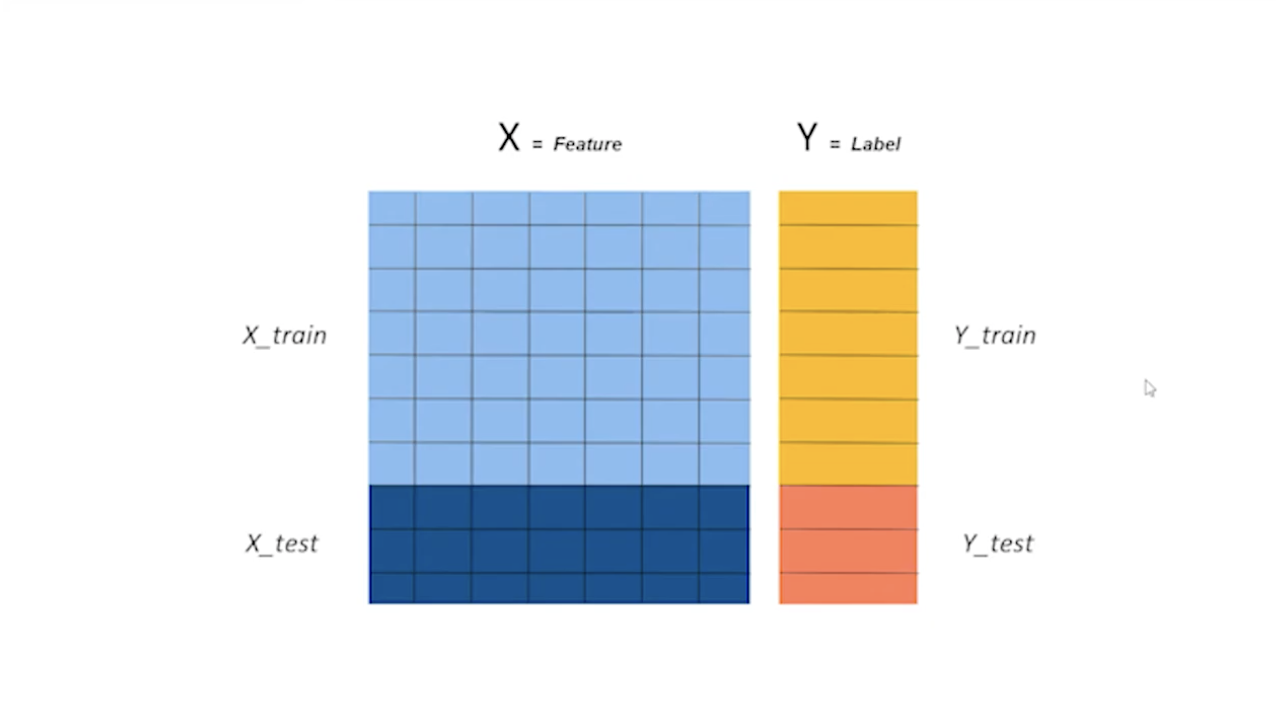
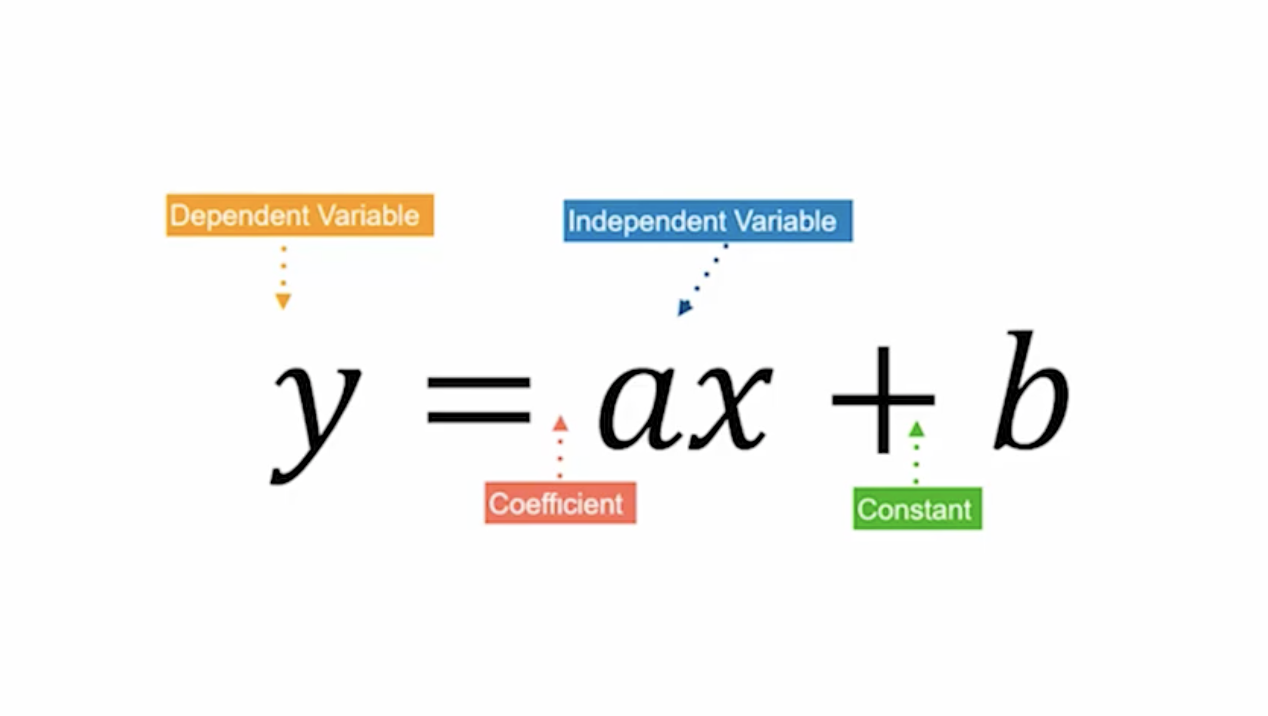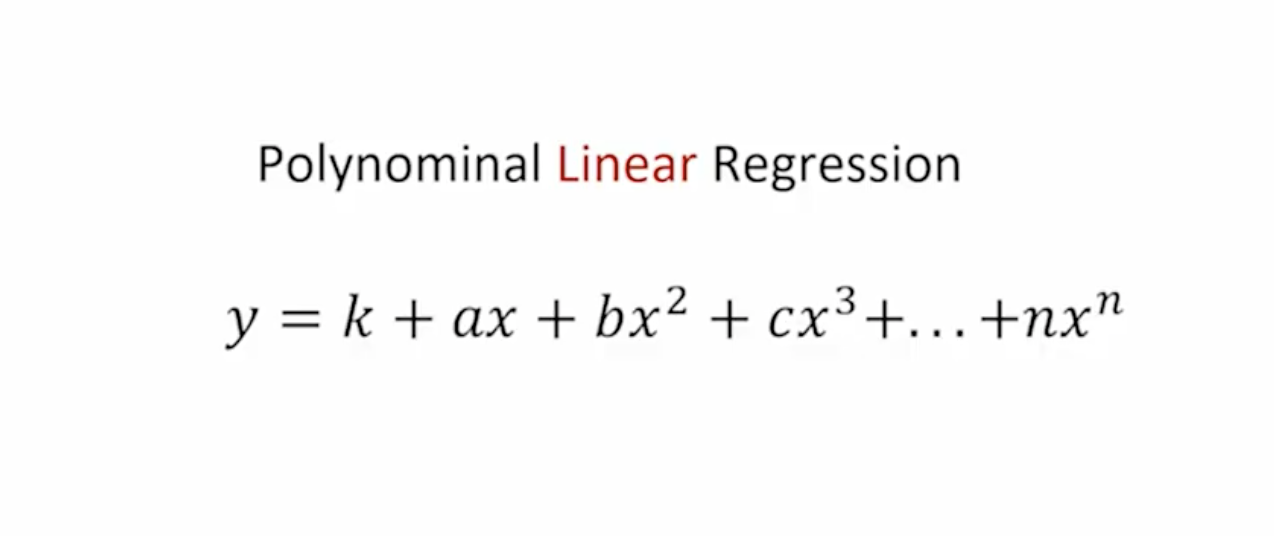Azure

[Azure](https://azure.microsoft.com/ko-kr/)는 Microsoft에서 제공하고 있는 아마존의 aws, 구글의 클라우드 플랫폼과 같은 클라우드 서비스의 이름이다.

Azure service 안에는 가상머신, 데이터 스토리지에 function, app service, web service 등 다양한 것이 존재한다. 그 중 하나가 AI 서비스이다.
Azure Machine Learning Studio
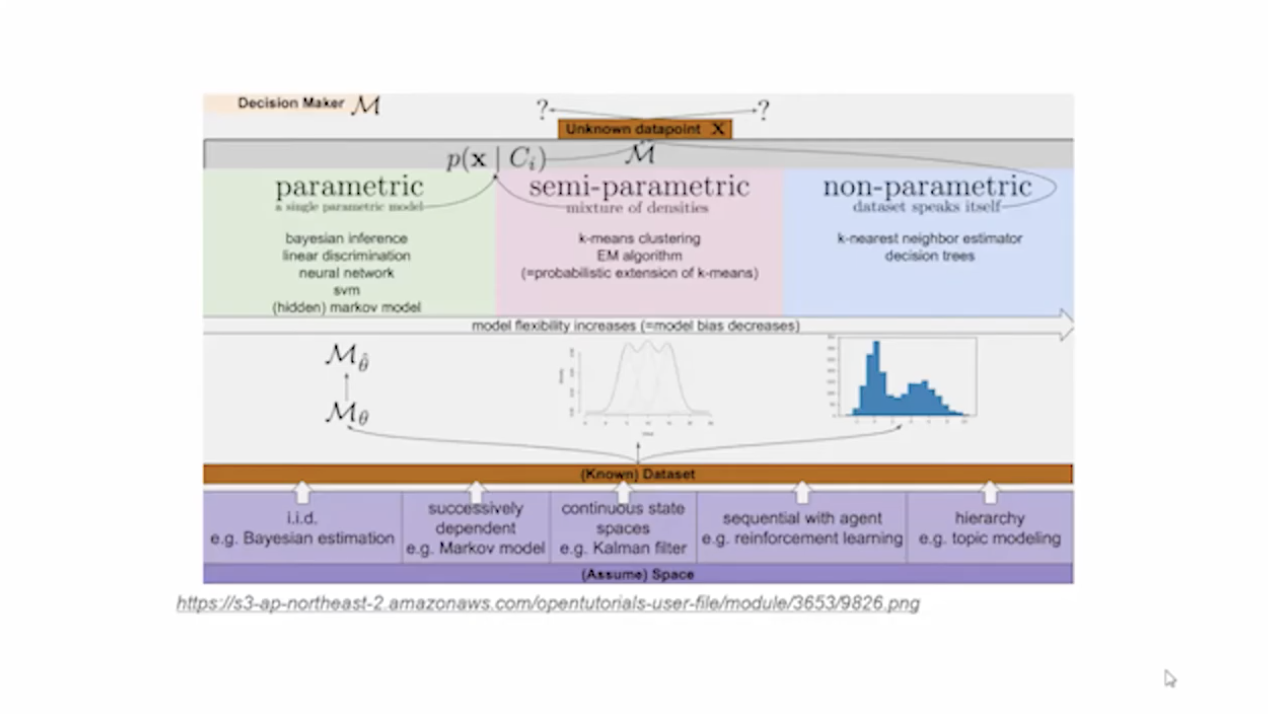
실제로 머신러닝을 구현하기 위해서는 Parametric, semi-parametric 과 같은 수식적인 개념을 알아야 하며, 그리고 나서는 그 안에 들어있는 알고리즘을 구현하기 위한 수식도 살펴봐야 한다.

이론을 살펴본 다음에는 주피터 노트북에서 파이썬 언어를 활용할 줄 알아야되며 케라스나 텐서플로우 아니면 SKlearn과 같은 것을 사용할 줄 알아야 한다.
이 뿐만 아닌 넘파이, 판다스 같은 기본 패키지들도 활용할 줄 알아야한다.
머신러닝 스튜디오를 사용하면 위와 같은 언어의 장벽 없이 머신러닝 모델을 손쉽게 만들 수 있다.
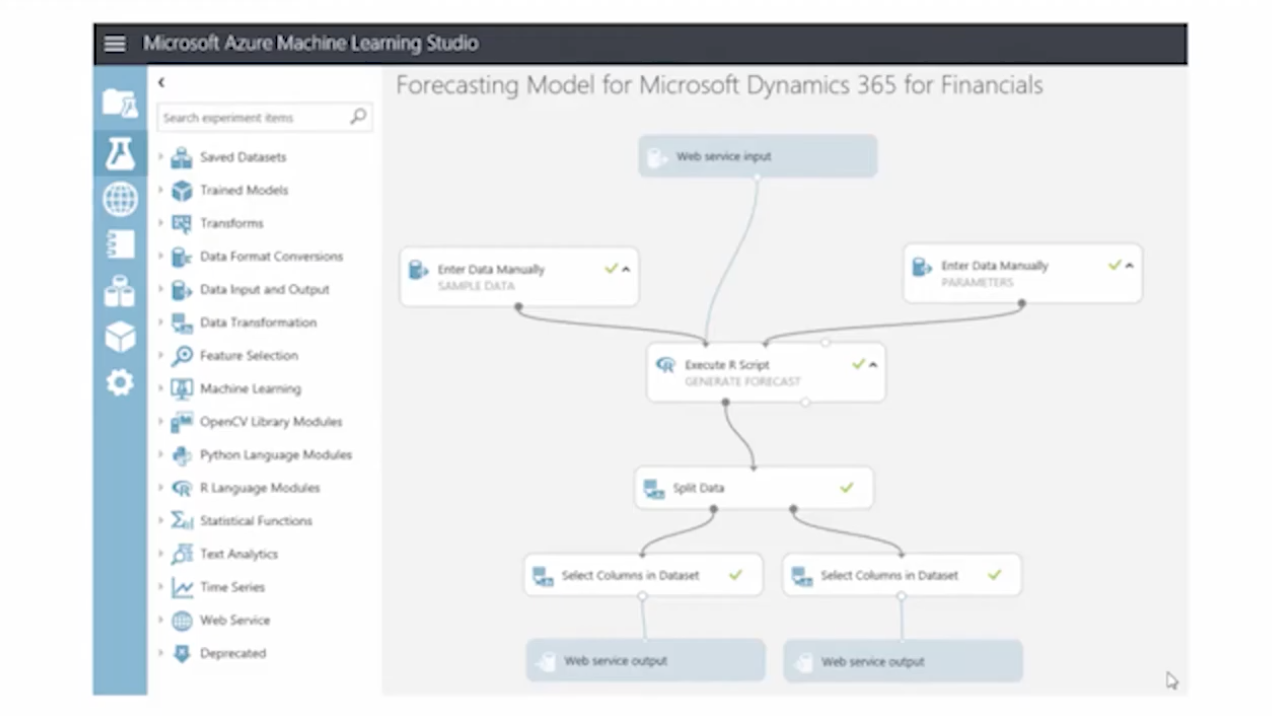
다음과 같이 코드가 전혀 없다. 기능 모듈을 만들어 그 모듈들을 퍼즐처럼 연결만 하면 원하는 프로그램을 간단하게 만들 수 있다.
- 정리
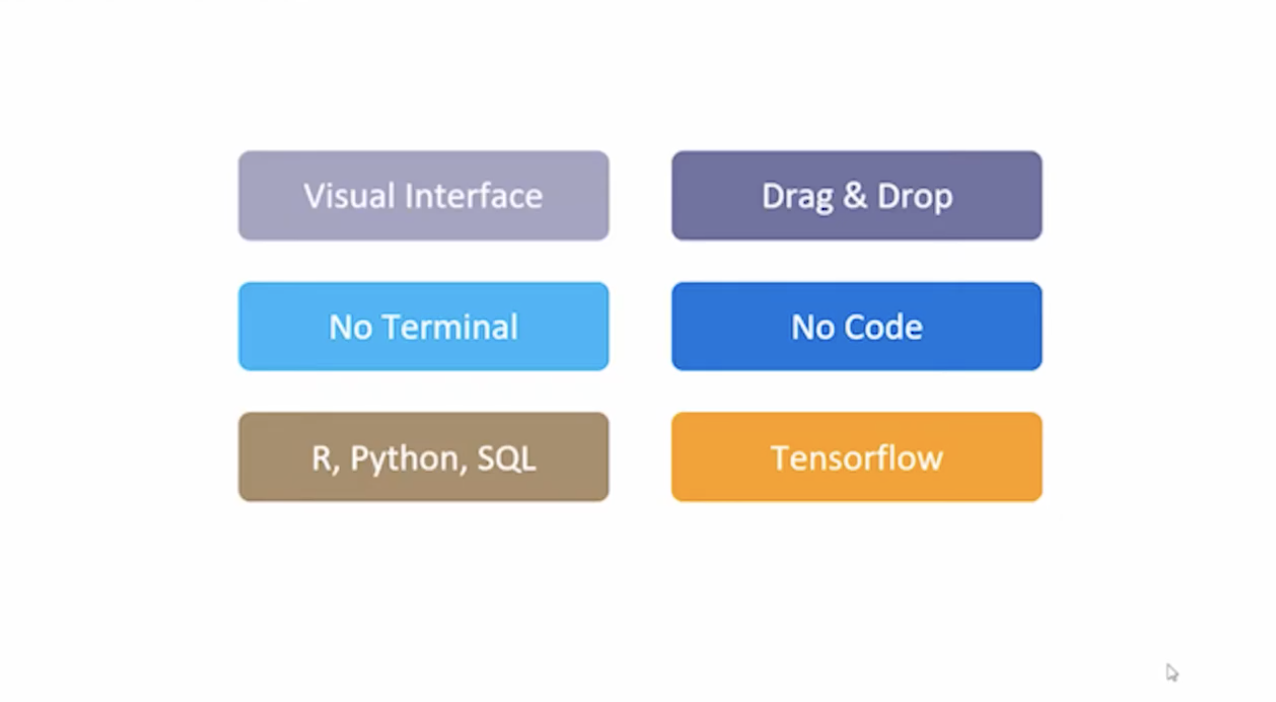
머신러닝 스튜디오는 비주얼 인터페이스를 가지고 있기 때문에 터미널을 켠다던지 코드를 사용할 필요 없이 단순히 네모 박스를 Drag & Drop 하고 연결함으로써 우리가 원하는 모델을 만들 수 있다.
R, 파이썬 등의 코드를 추가하는 것도 가능하며 텐서플로우, 케라스와 같은 프레임워크를 같이 연동해서 사용하는 것도 가능하다.
- workflow
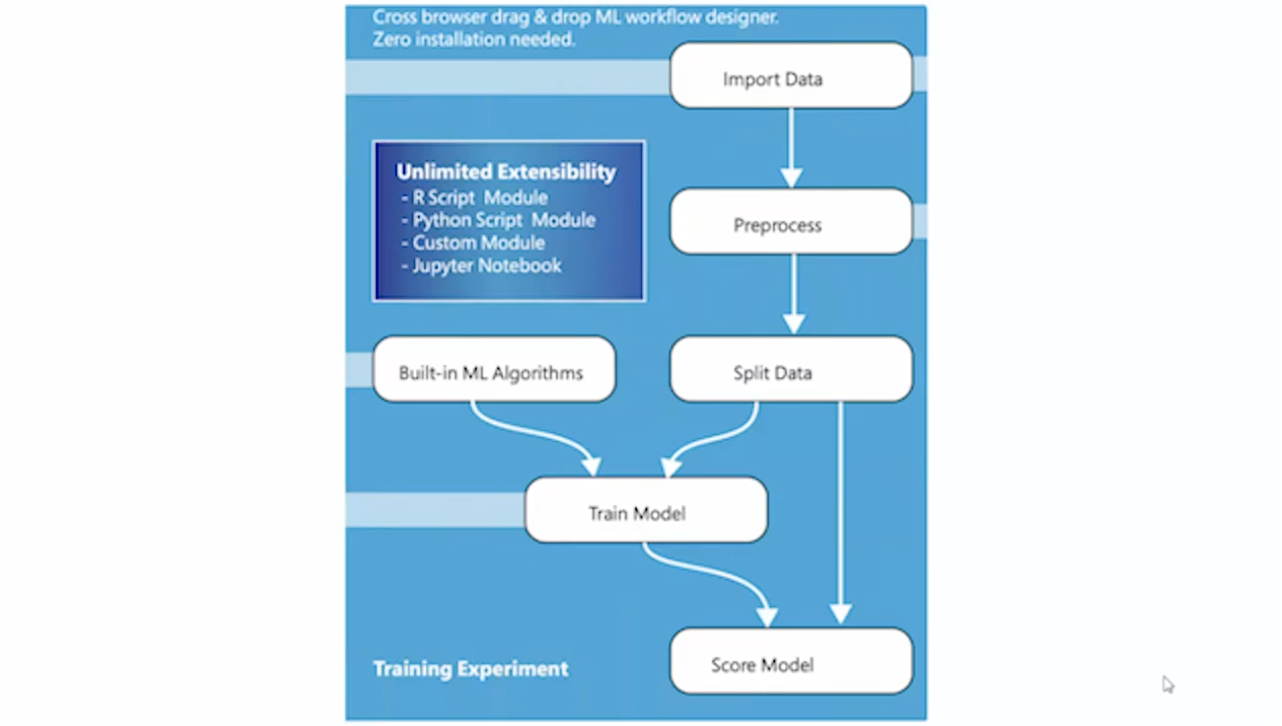
- 문제를 정리
- 데이터 셋을 준비
- 데이터를 학습 시키기 위한 모델 설정
- 모델을 훈련/평가
- 모델 활용
위 다섯 플로우를 ML 스튜디오에서 지원한다.
ML 스튜디오를 실제로 사용한다면 크게 데이터 전처리와 모델 학습/예측 으로 나눌 수 있다.
- part1. 데이터 전처리
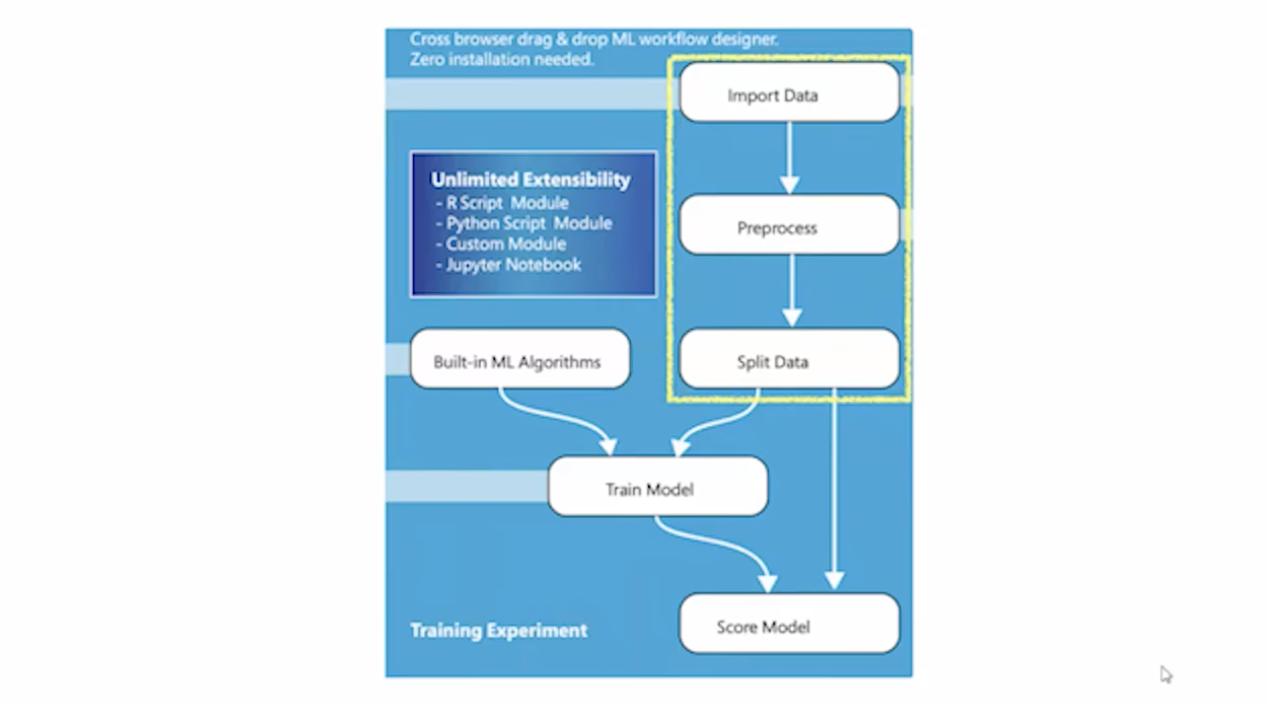
먼저 데이터를 전처리하는 하는 부분에서 먼저 데이터를 가지고 오는 것부터 시작한다. 데이터를 가지고 와서 전처리하고, 나누는 것까지 데이터 전처리라고 부른다.
- 데이터 지원 형식

지원 가능한 데이터 형식에는 csv, txt, Excel 파일, Azure 테이블, Hive 테이블, SQL 데이터베이스 테이블, zip 등의 거의 모든 데이터 형식을 지원한다.

지원되는 데이터의 포멧으로는 String, Integer, Float, Double, Boolean, Date Time, Timespan이 있다.
여기서 DateTime은 정확한 시간, 날짜를 의미하며 Timespan은 언제부터 언제까지의 시간, 기간을 의미한다.
업로드할 수 있는 한 개의 최대 용량은 1.89GByte까지이며, 이런 파일들을 최대 10GByte까지 업로드해서 활용할 수 있다.
(유료버전은 더 크다.)
- 데이터 전처리 과정
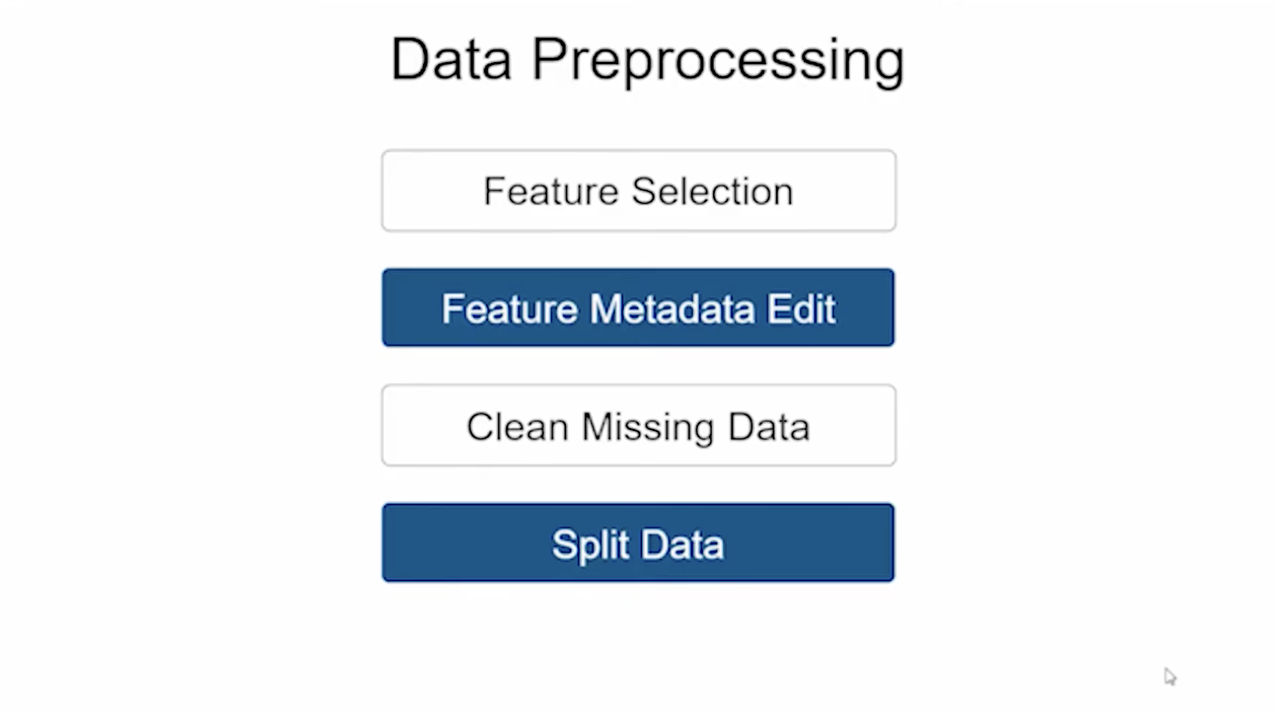
첫 번째로 Feature Selection 과정이다.
필요한 컬럼과 필요하지 않은 컬럼들을 선택하는 과정으로 Feature Selection을 한 다음에는 선택된 Feature에 대해서 Metadata Editing을 해주게 된다.
선택된 피처의 메타데이터를 수정하는 과정을 거치게 된다.
그 다음으로는 Clean Missing Data로 데이터가 빠짐없이 모두 다 잘 들어가 있지 않은 경우 빠져 있는 값들을 삭제한다던지 다른 값으로 채워주는 작업을 한다.
여기까지 진해오디고 나면 데이터 훈련 셋과 테스트 셋 두 개의 셋으로 분리를 하게 되고 데이터 전처리를 완료한다.
- part2. 모델 학습 / 예측
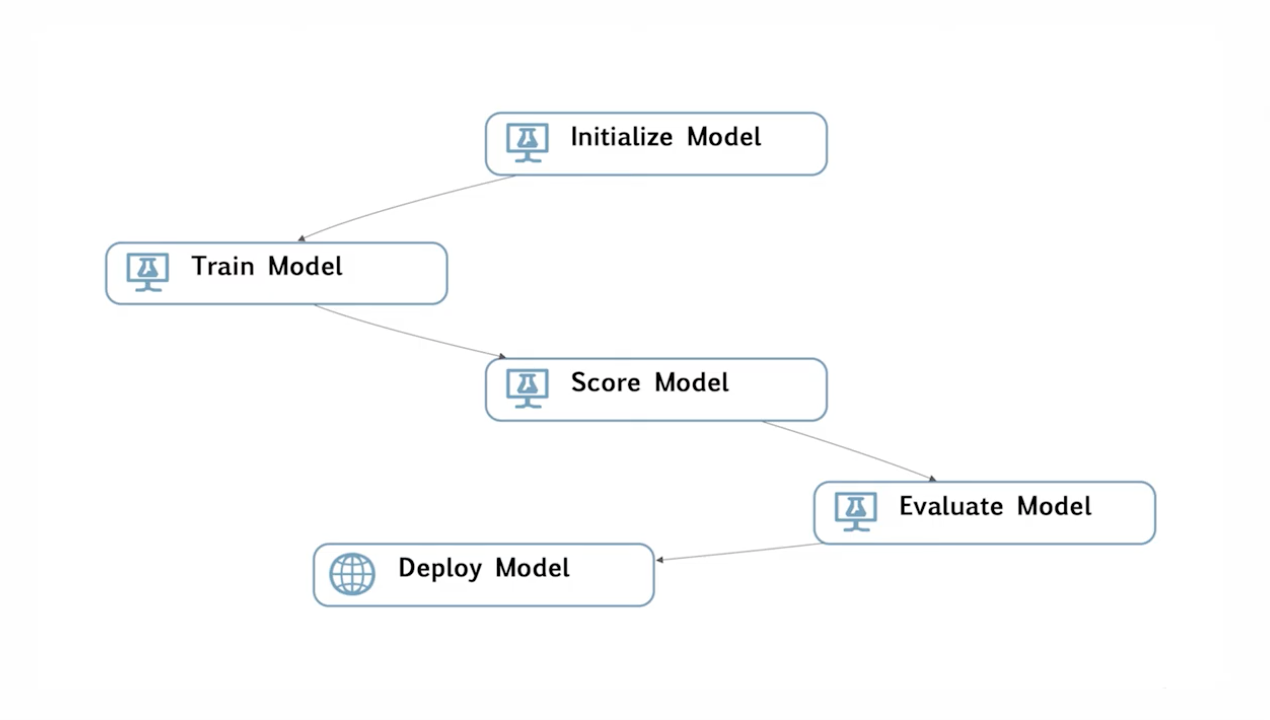
모델을 학습시키는 과정은 위 사진과 같이 다섯 단계로 진행된다.
첫 번째(Initialize)는 어떤 알고리즘을 활용할 것인지 선택한다.
두 번째(Train Model)는 준비한 훈련 데이터와 연결해서 실제로 학습을 시키게 된다.
세 번째(Score Model), 네 번째(Evaluate Model)는 학습을 다 끝내고 나면 만들어진 모델이 정말로 잘 만들어졌는지 판단하기 위해 테스트 셋을 이용해서 스코어링 평가를 진행하게 된다.
마지막(Deplay Model)으로 모델을 배포하게 된다.
Machine Learning 종류
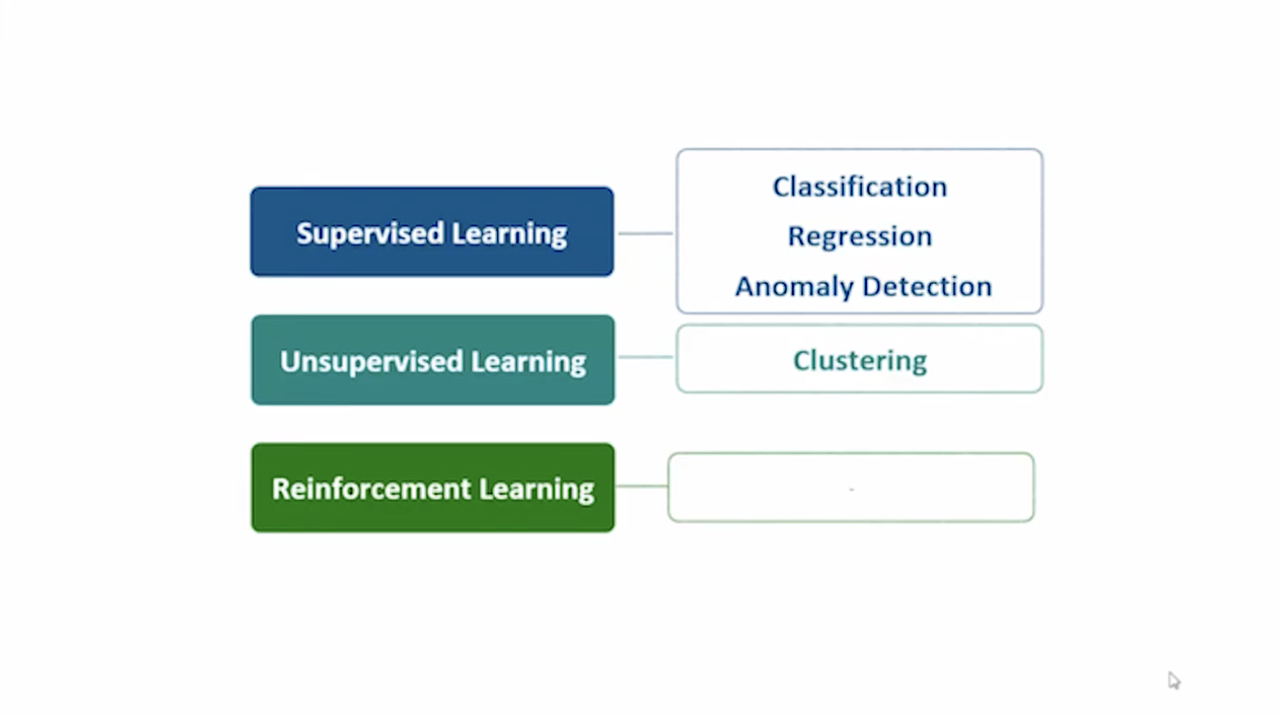
Supervised Learning, Unsupervised Learning, Reinforcement Learning 이렇게 세 가지 중에서 ML 스튜디오에서는 Supervised Learning, Unsupervised Learning 이렇게 두 가지를 제공한다.
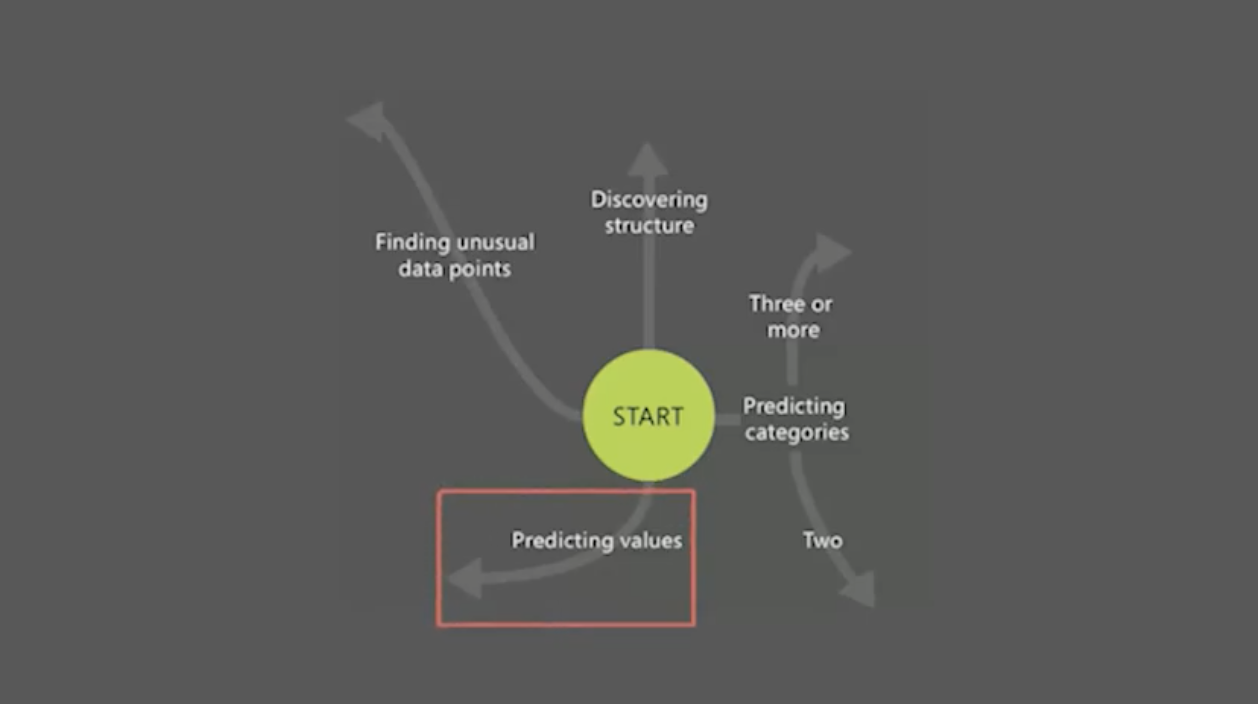
Supervised Learning(정답과 문제가 함께 제공(지도 학습))에서는 Classification, Regression, Anomaly Detection 세 가지 문제를 풀 수 있다.
Unsupervised Learning(정답이 필요 없는 경우(비지도 학습))에서는 Clustering 그룹화 문제를 풀 수 있다.
강화 학습은 미지원이다.
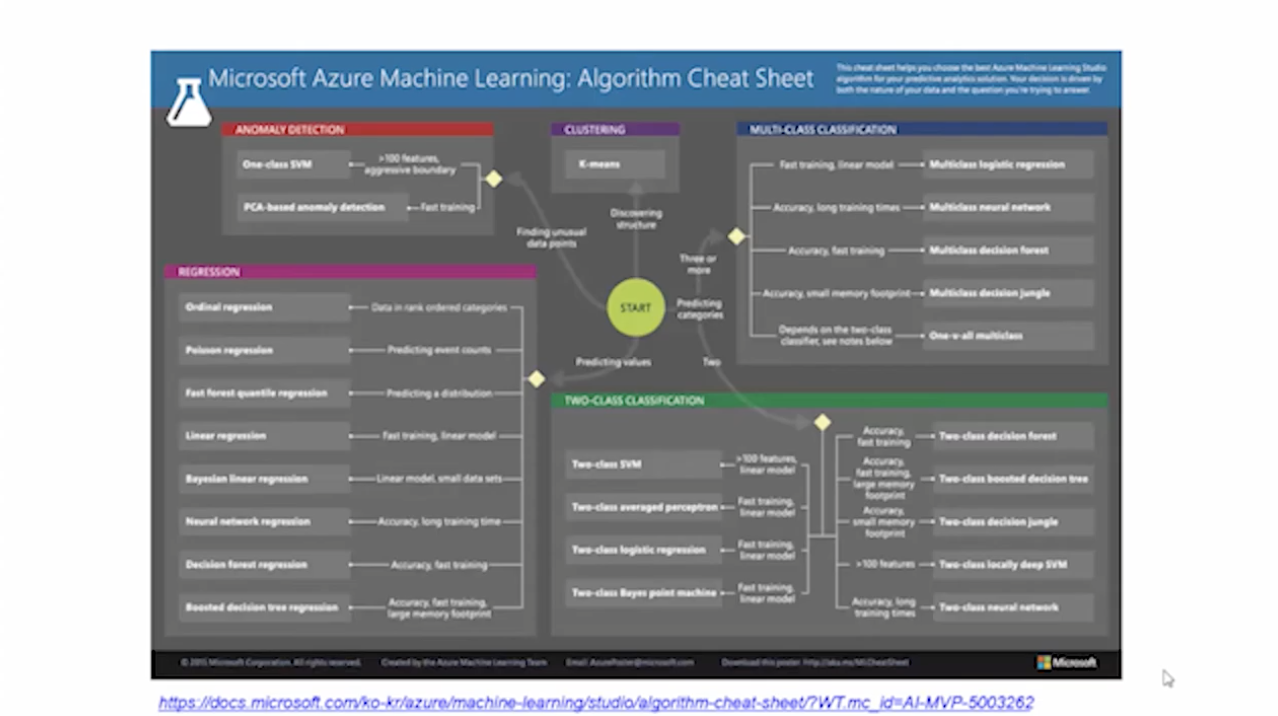
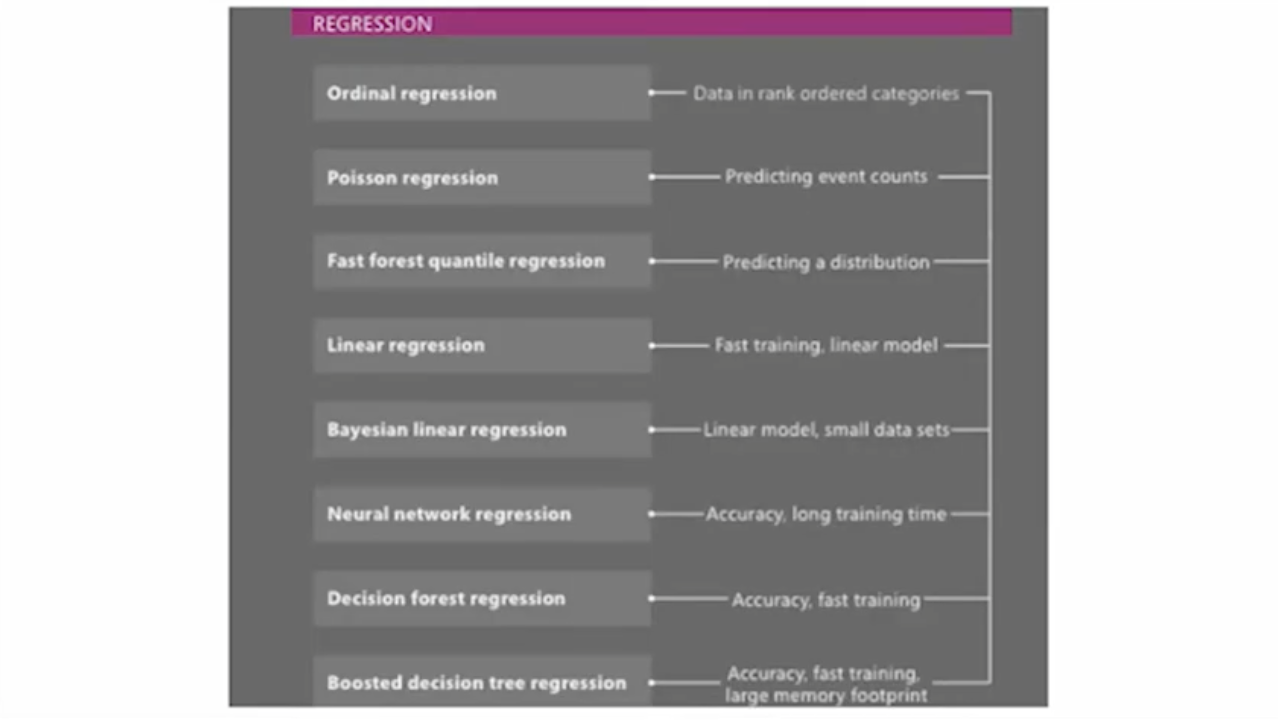
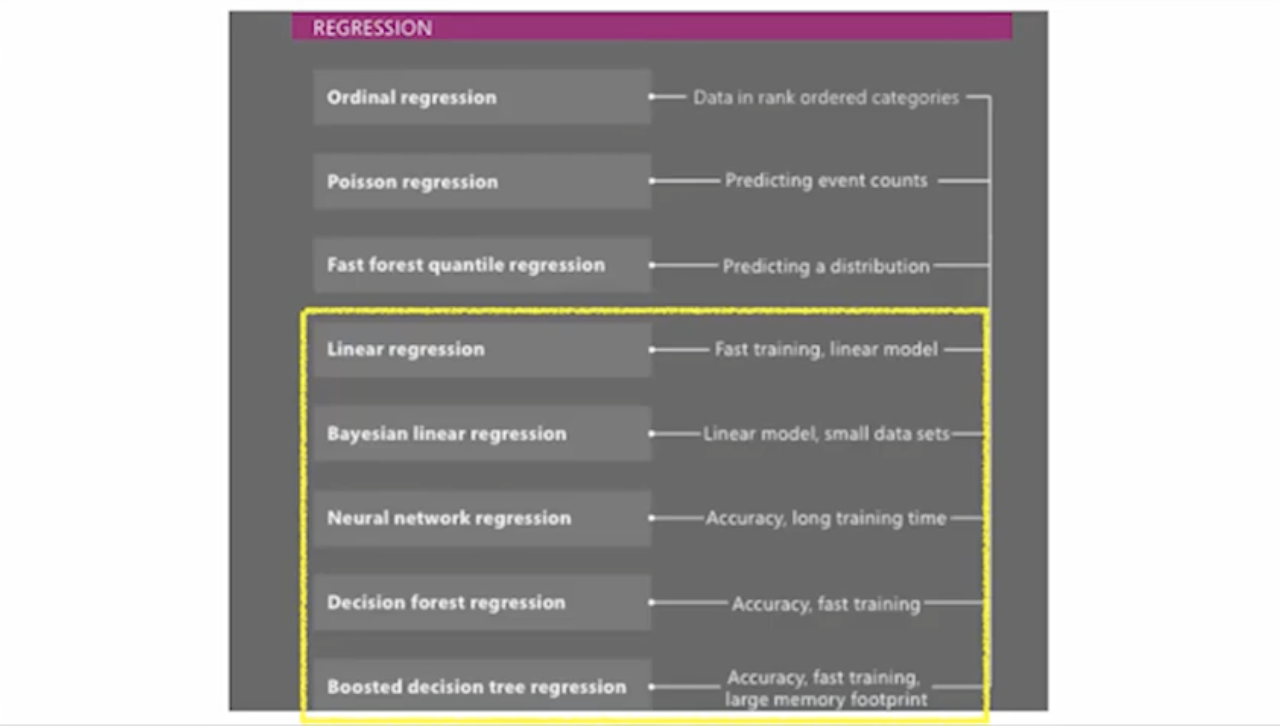
ML 스튜디오에서 25개의 알고리즘을 제공한다.
어떤 알고리즘을 선택해야할 지 모를 때는 Algorithm Cheat Sheet을 확인하면 된다.
실습
우선 Azure Machine Learning Studio 가입 & 로그인한다.
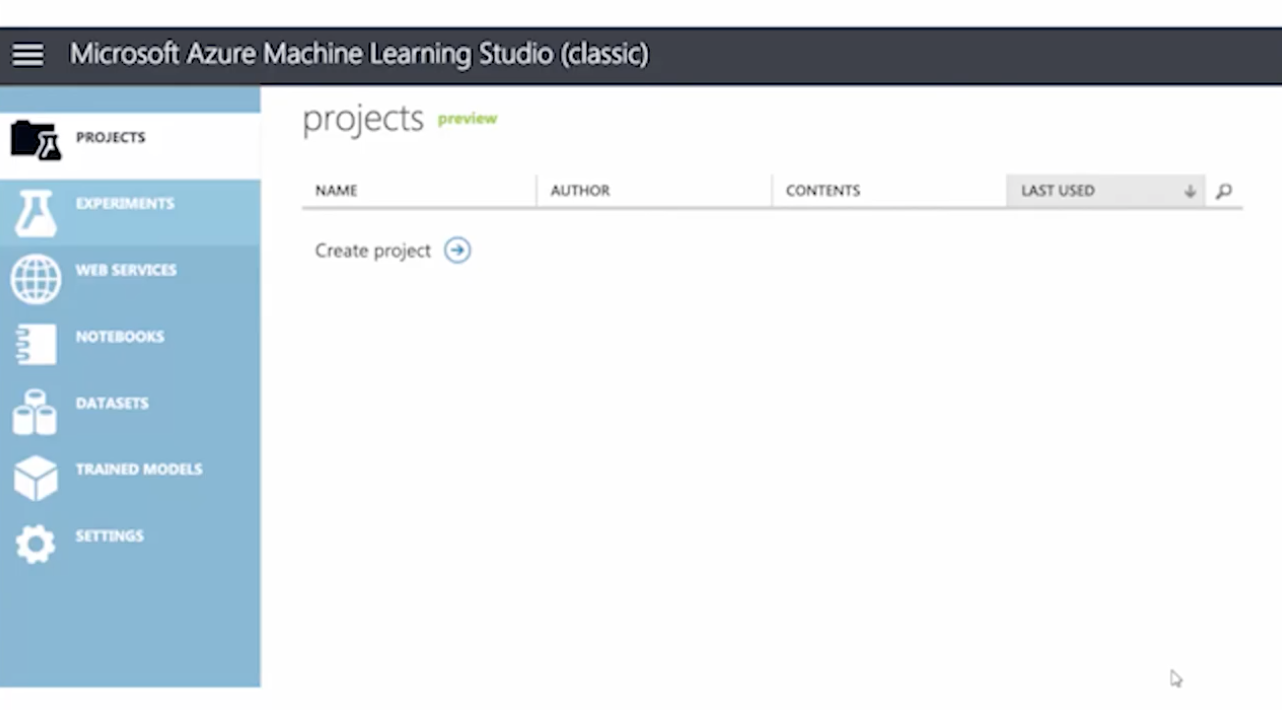
MLStudio는 총 7개의 큰 메뉴로 구성되어 있다.
- Project : 전체적인 관리하는 메뉴
- 모델을 넣어 놓거나, 데이터를 모아둘 수 있다.
- Experiments : 실제로 실험이 만들어지고 저정되고 확인할 수 있는 공간
- Web Services : 학습시킨 모델을 웹상에 배포하게 된 경우 웹 서비스 메뉴에서 배포된 모델을 확인할 수 있다.
- Notebooks : 파이썬 코드, R 코드를 추가하여 기능을 만들 때 사용한다.
- DataSets : 내 컴퓨터에 있는 데이터나, 서버에 있는 데이터를 연동해서 올리는 공간이다.
- Samples : Microsoft에서 가지고 있는 데이터를 샘플로 제공하는 공간이다.
- Trained Models : 학습 시켰던 모델들이 리스트 되어 나타나느 공간이다.
- Settings : ML 스튜디오를 사용하는 데 관련된 여러 가지 설정값을 수정할 수 있는 공간
- 공유해서 작업하는 공동 작업 설정 또한 셋팅에서 설정한다.
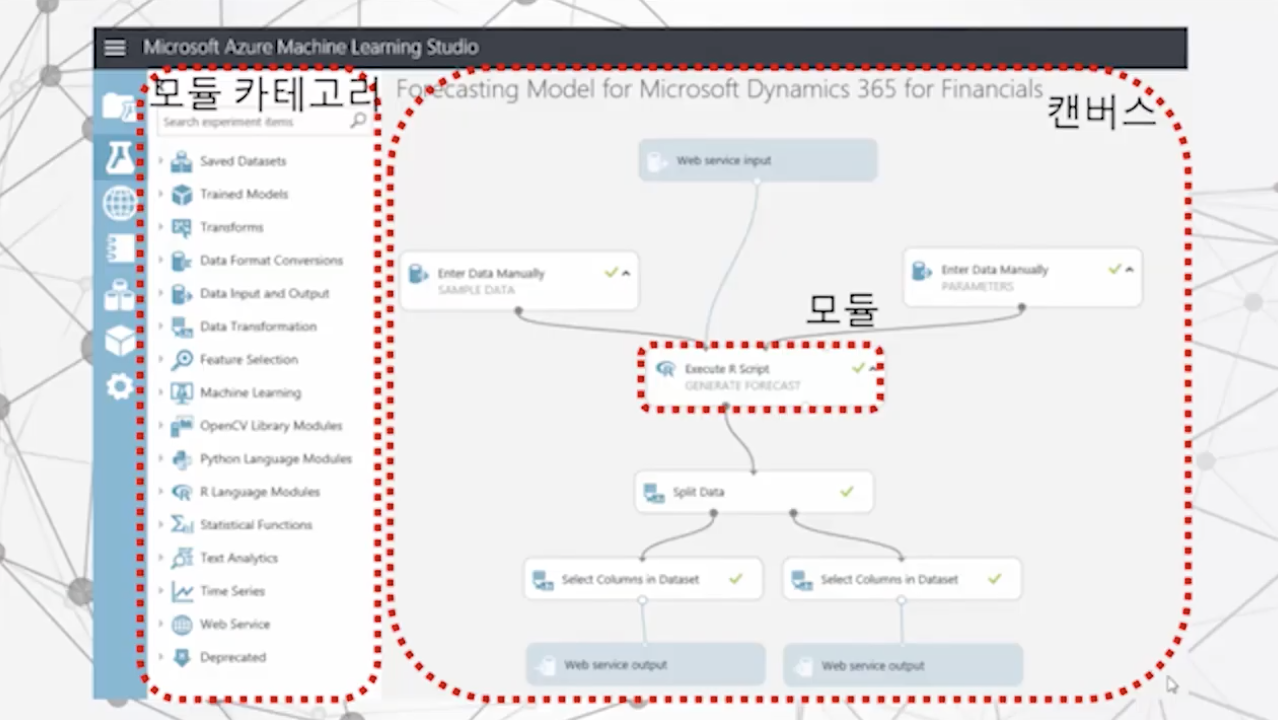
Experiments의 화면이다.
왼쪽에 모델 카테고리에서는 111개의 모듈들이 존재한다.
우측 캔버스는 모듈과 모듈을 연결해서 하나의 모듈을 그림처럼 만들어내는 곳이다.
모듈은 네모 모양이며, 모듈의 위쪽에 위치하는 동그라미는 Input을, 아래쪽에 위치한 동그라미는 Output을 의미한다.
모델 카테고리에 있는 모델들을 캔버스로 드래그 앤 드롭 한 뒤, 모듈들끼리 실로 연결하면 작업 플로우가 완성 되는 형태이다.