머신러닝과 딥러닝
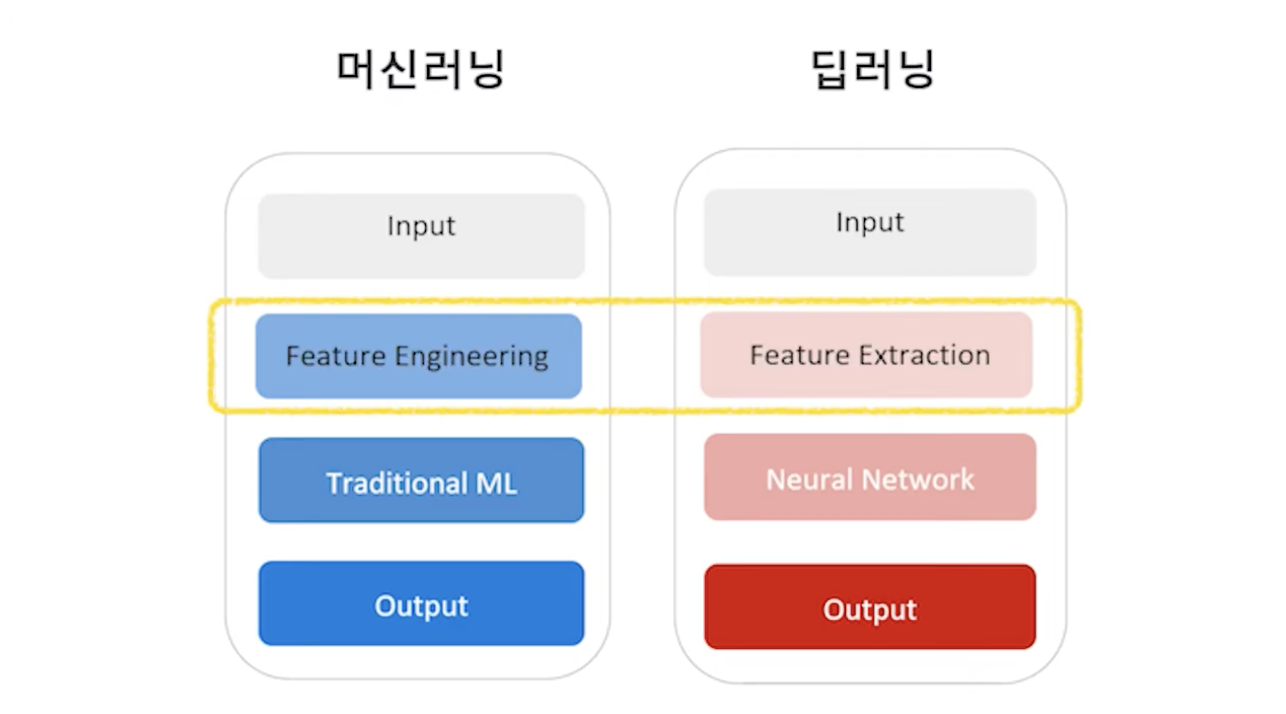
머신러닝과 딥러닝 모두 처음에 인풋 데이터를 받아서 어떤 것을 처리한 다음 머신러닝은 전통적인 머신러닝 모델을 사용하며, 딥러닝은 뉴럴 네트워크를 활용하여 아웃풋을 내는 전반적인 흐름은 동일하다.
그 안에 비어있는 무언가가 차이점인데, 이 차이는 바로 Feature Engineering을 하느냐, 아니면 Feature Extraction이 일어나느냐의 차이이다.
- Feature Engineering
Feature Engineering이란 사람이 여러 개의 Feature가 있을 때 어느 것이 최종 아웃풋에 영향을 미칠지 아닐지를 고려해 가면서 변수를 조정하고 빼는 것을 말한다.
Feature Engineering은 단어 자체가 추출하다 라는 뜻으로 기계가 Feature에서 바로 특징을 뽑아내는 것이기에 사람은 Feature를 따로 건드리지 않는다.
그렇기에 딥러닝에서 자체적으로 모델이 해주는 것이기 때문에 사람의 손이 덜 가고 그 도메인에 대한 이해가 머신러닝에 비해서는 덜 필요하다.
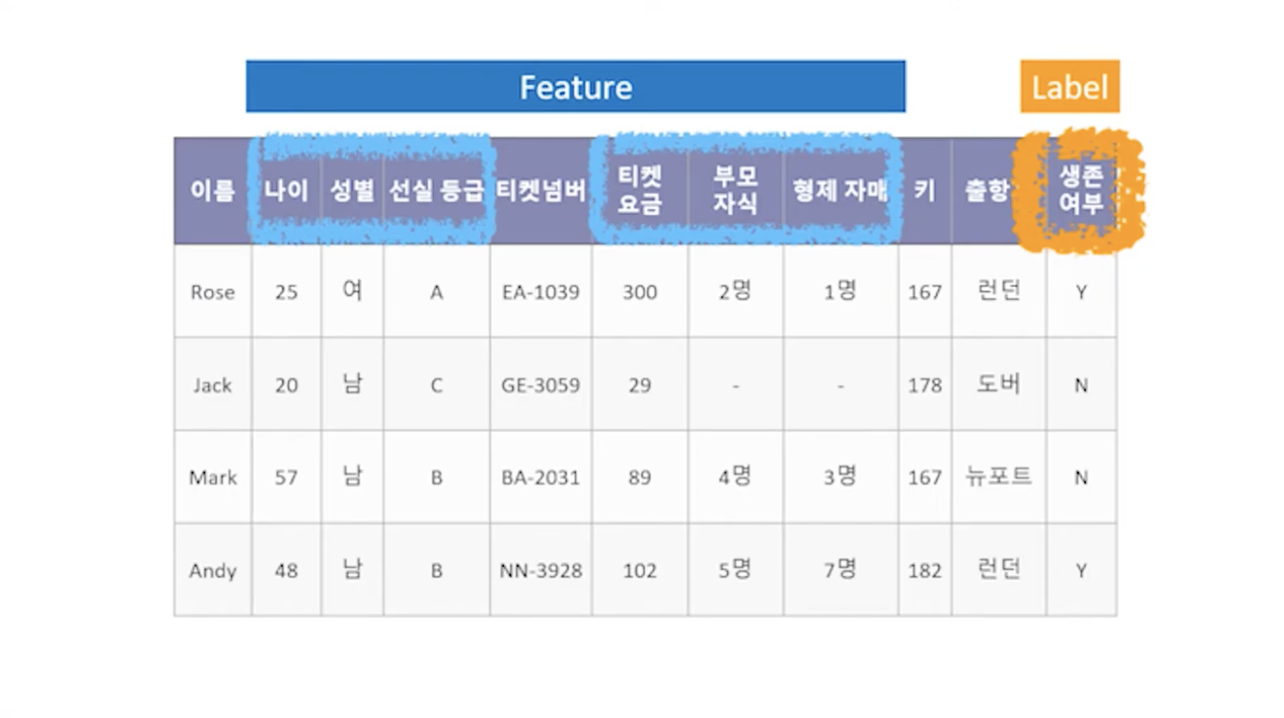
위 사진은 타이타닉의 생존자, 생존하지 못한 사람들의 데이터를 나열한 것이다.
사람들의 이름, 나이, 성별, 선실 등급 등의 데이터 그리고 그 사람이 생존했는지 아닌지의 여부가 나타나있는데 생존 여부에 영향을 미치는 데이터가 무엇인지, 칼럼을 하나하나 보면서 이게 최종 아웃풋에 영향을 끼칠지 끼치지 않는 건지 생각해가며 골라내는 작업이 바로 Feature Engineering이다.
컬럼 하나하나 어떤 의미인지, 이게 어떠한 영향을 미칠지 아닐지를 생각해야 하기 때문에 그 도메인에 대한 지식도, 경험도 있어야 하며 feature Engineering 하는 시간도 꽤 오래 걸린다. 그렇기 때문에 데이터를 잘 이해하고 있어야 한다.
- Feature & Label
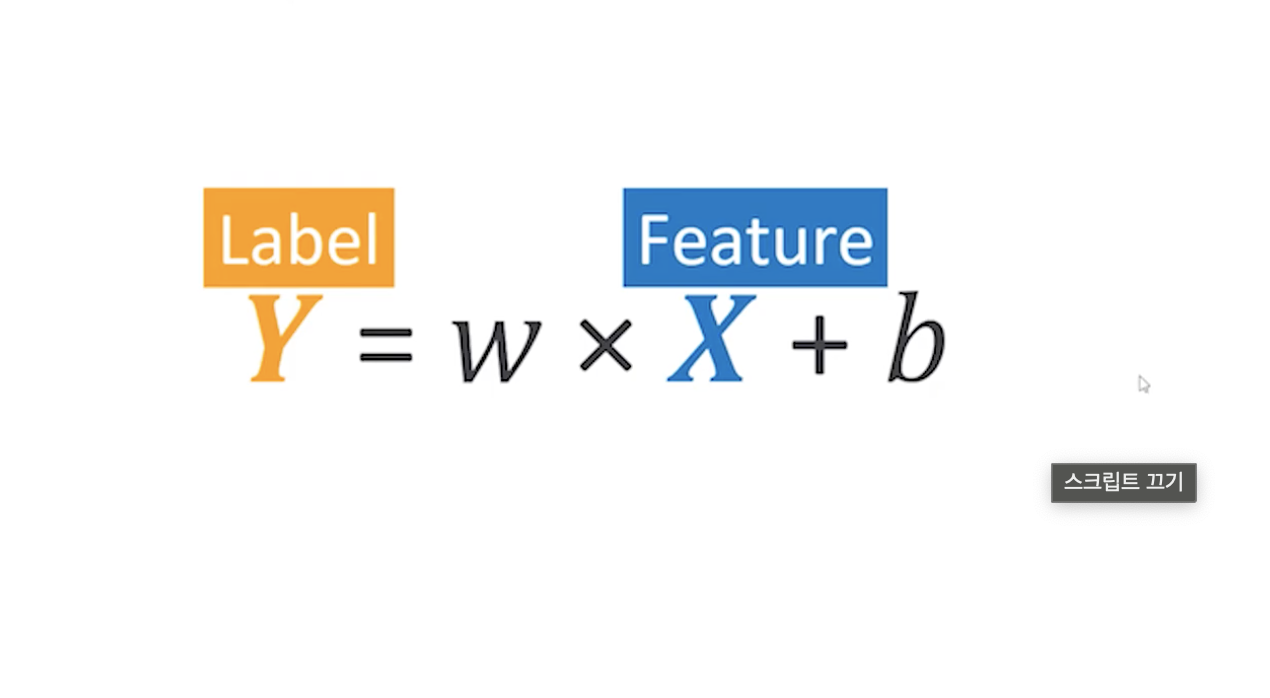
우리가 알고 싶은 값 Y가 Label이 되며, 변수인 X가 바로 Feature가 된다.
X가 어떻게 변하냐에 따라서 Y가 변하게 되는 것이며, Y는 우리가 정답이라고 이야기 하며 Tag, Target, Label 등 다양한 이름으로 부르고 있다.
즉, Feature는 최종적인 Label에 영향을 끼치는 변수이며, Feature가 변하는 것에 따라 Y가 어떻게 변하는지를 우리가 구하고 싶은 것이다.
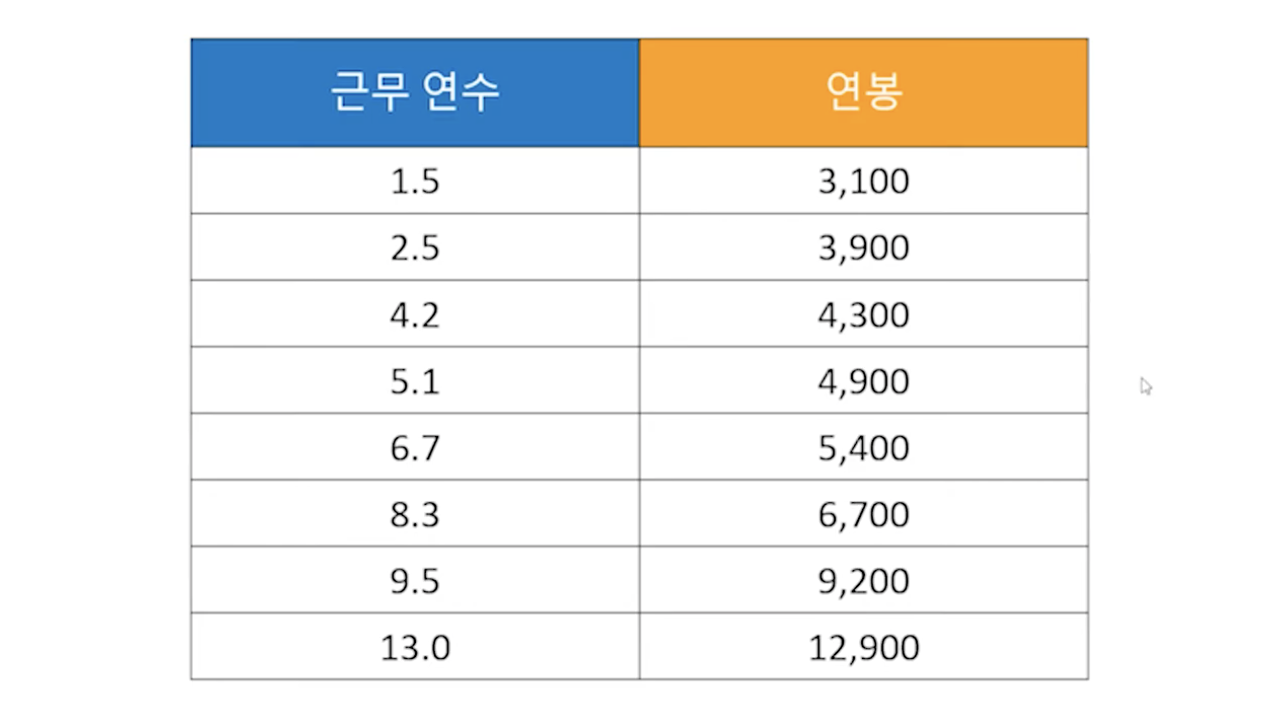
예를 들어 근무 연수에 따른 연봉 변화 데이터가 있을 때 Feature는 근무 연수가 되는 것이며, 연봉이 레이블 결과값이 되는 것이다. 연봉에 따라서 근무 연수가 바뀌는 것이 아닌, 근무 연수가 몇 년이냐에 따라서 연봉이 결정되기 때문이다.
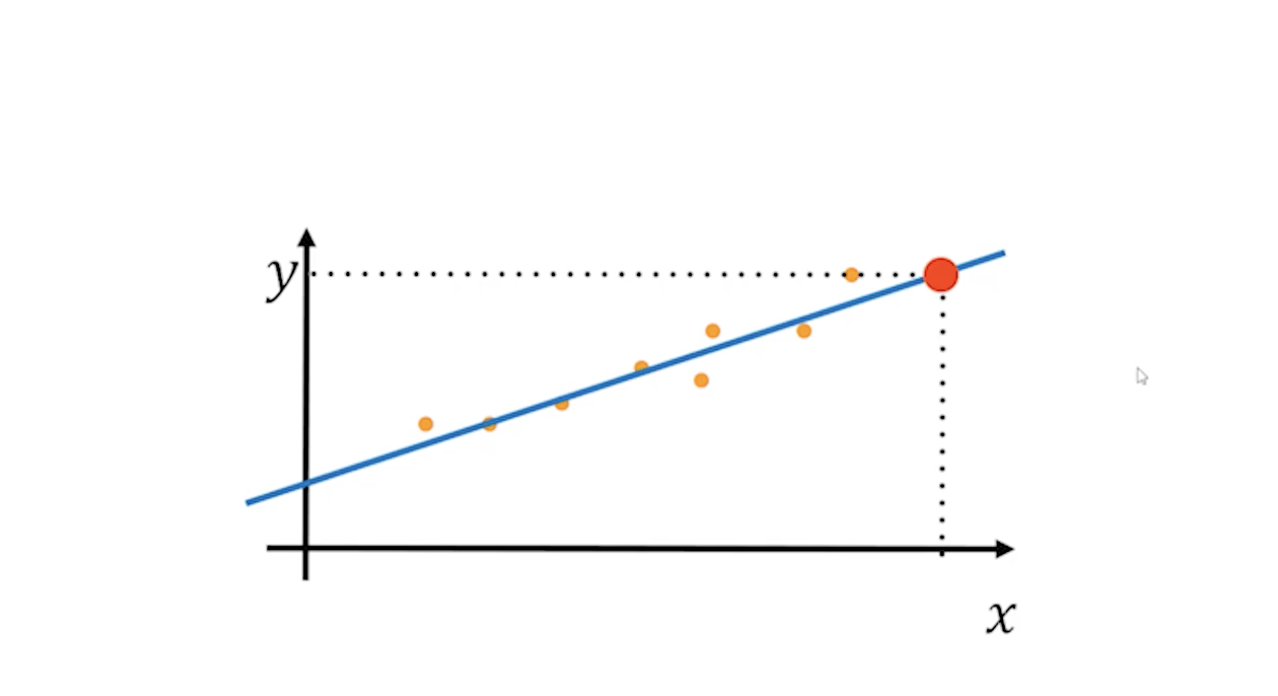
위 데이터에서 X와 Y축의 데이터를 찍은 뒤, 데이터를 기준으로 선을 그릴 수 있다. 이 선을 따라서 우리는 나중에 모르는 X값을 추측하고 싶을 때 이 직선 값을 대입해서 모르는 Y값을 구할 수 있게 되는 것이다.
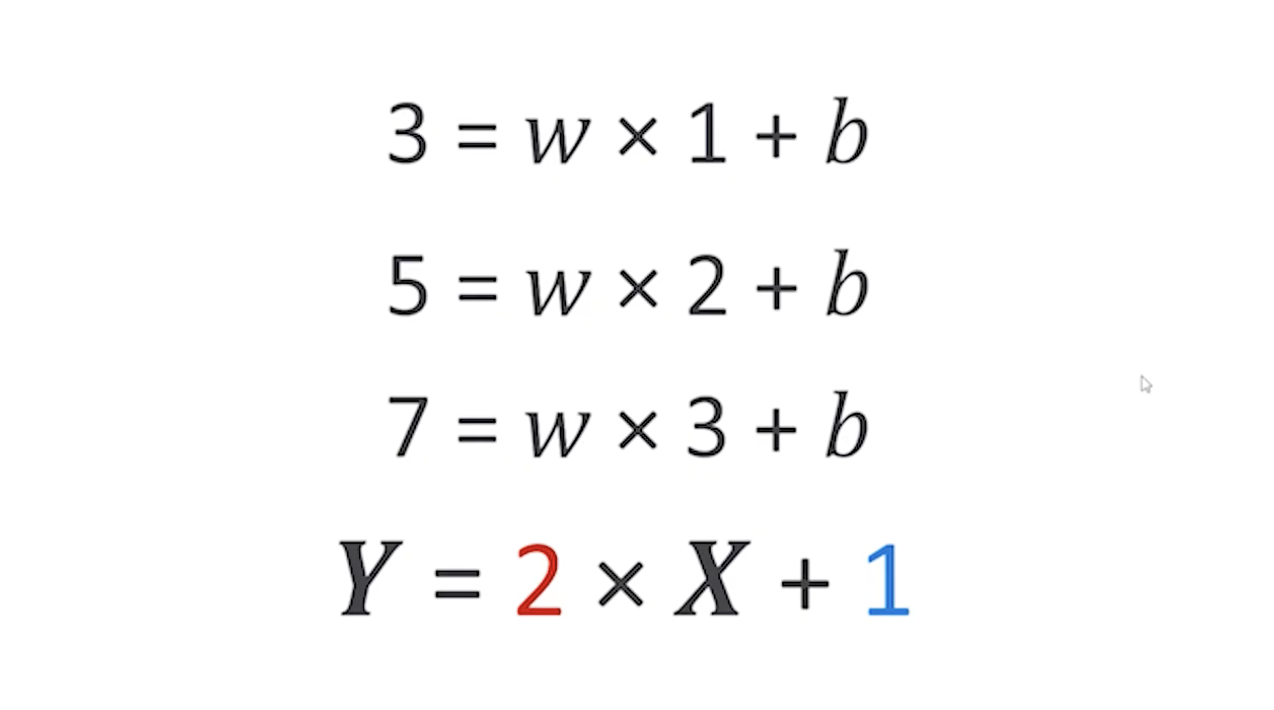
X에 1을 넣었더니 3이 나오고, 2를 넣었더니 5가 나오고, 3을 넣으면 7이 나온다는 데이터를 가지고 있을 때 우리는 w는 2, b는 1이라는 값을 구할 수 있다. 이러한 작업이 바로 머신러닝이 하는 것이다.
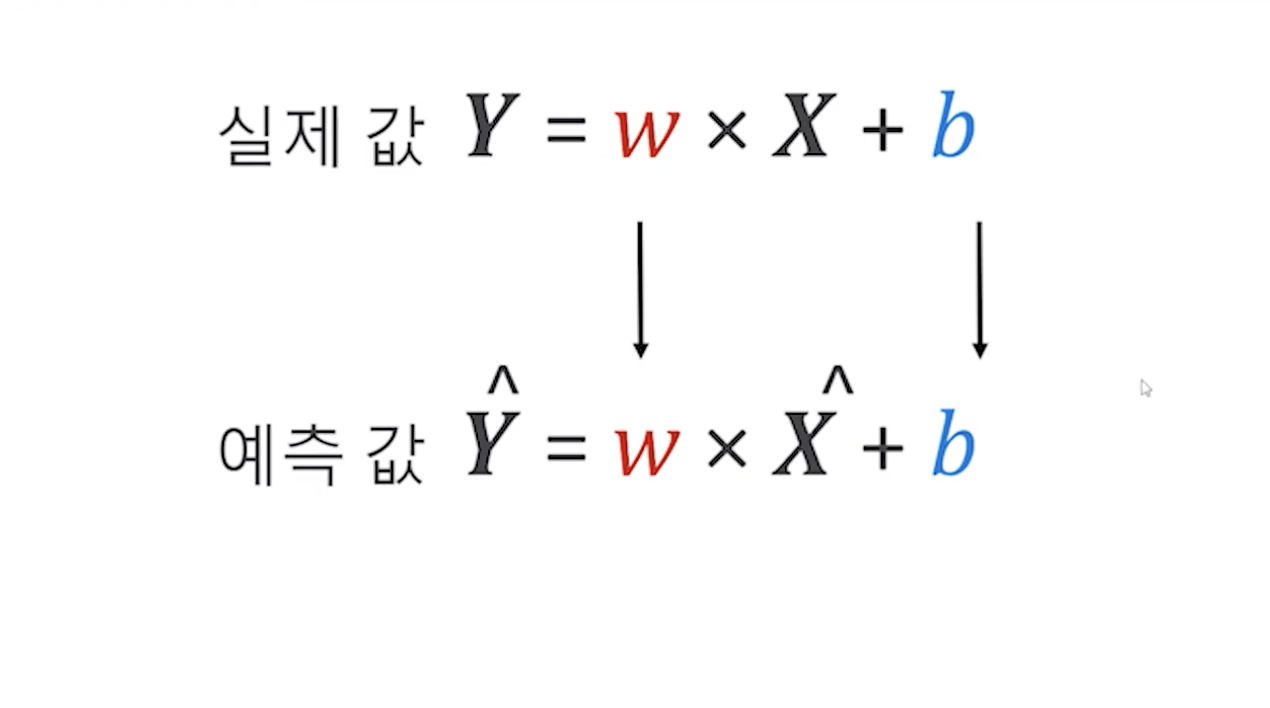
이차방정식이나 3차 방정식 등 데이터가 훨씬 더 복잡해지고 양이 많아지게 된다면 인간이 구하기가 힘들어지기 때문에 컴퓨터의 도움을 받는다.

즉, 딥러닝, 머신러닝이라 할 때 붙는 러닝은 바로 이 w와 b를 학습하기위해 데이터를 다량으로 보면서 진행한다는 것을 의미한다.
DATA
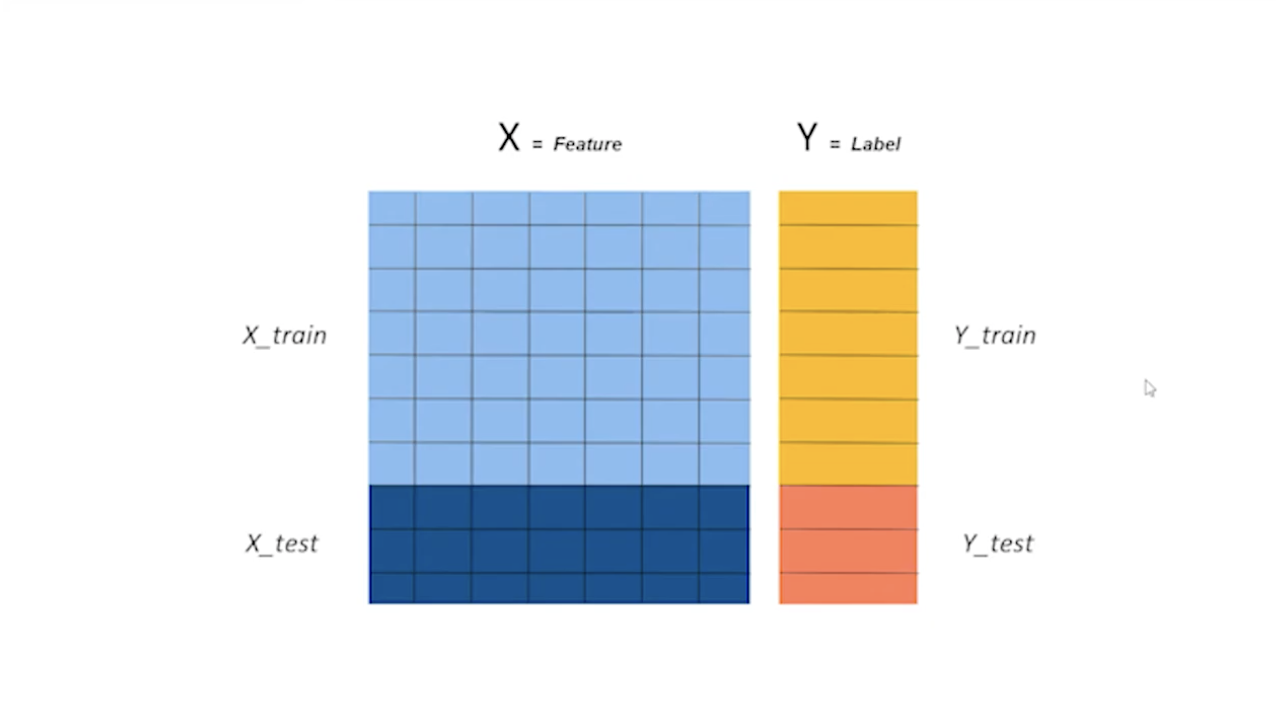
X(Feautre)는 모두 다 변숫값이 여러 개 칼럼으로 나와 있다. 이렇게 데이터가 주어진다면 모든 데이터를 전부 다 학습하는데 사용하지 않는다. 이 중에서 70%는 학습을 하는데 사용하며, 사용하지 않는 나머지 30%는 평가하기 위해서 사용한다.
- Random Split
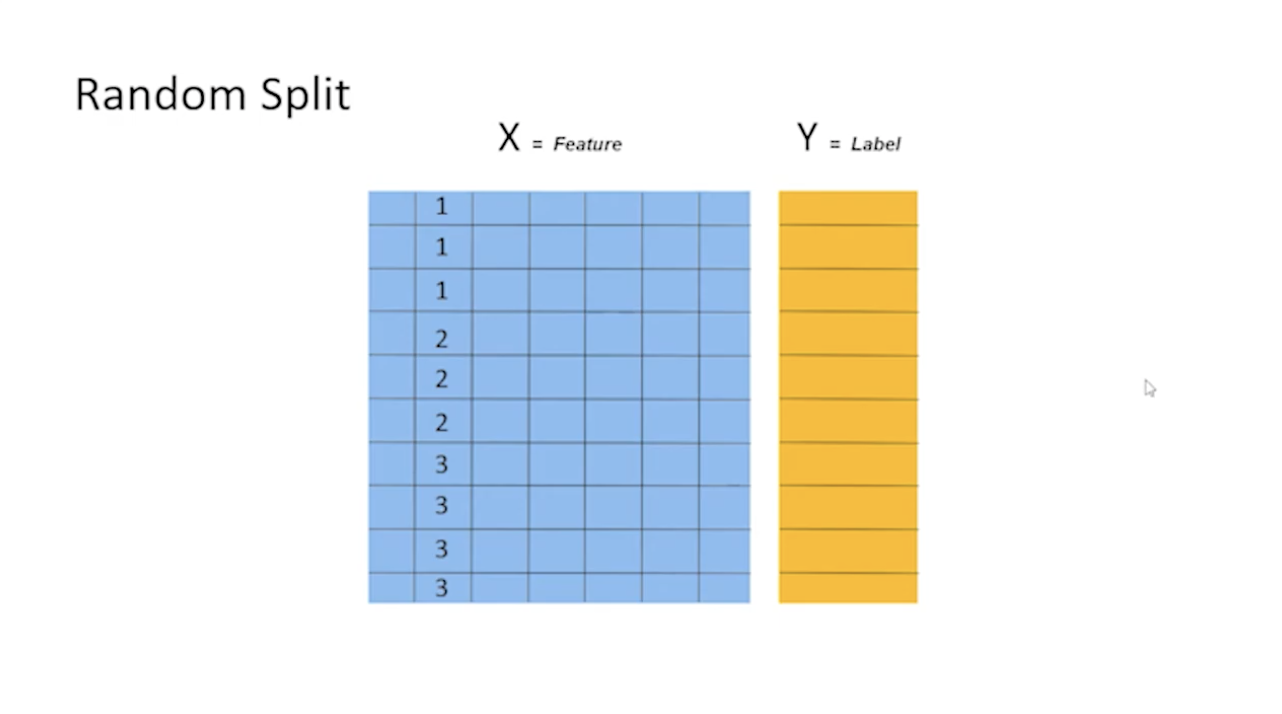
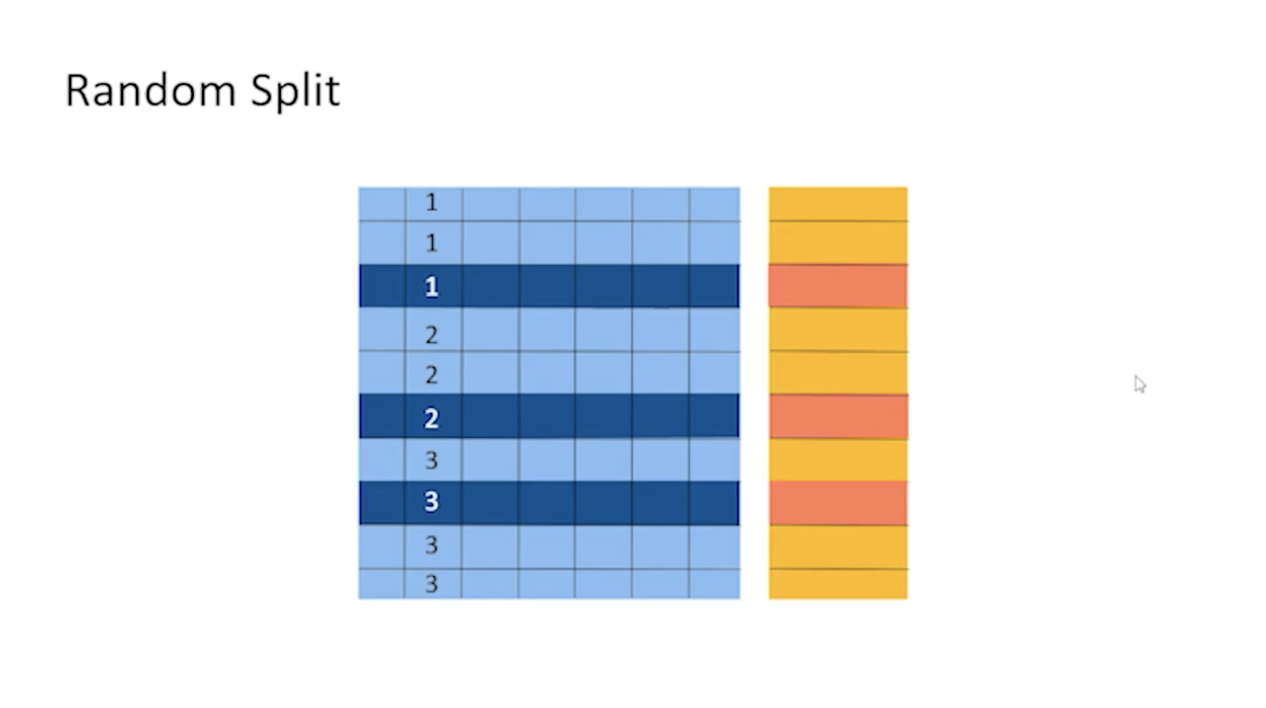
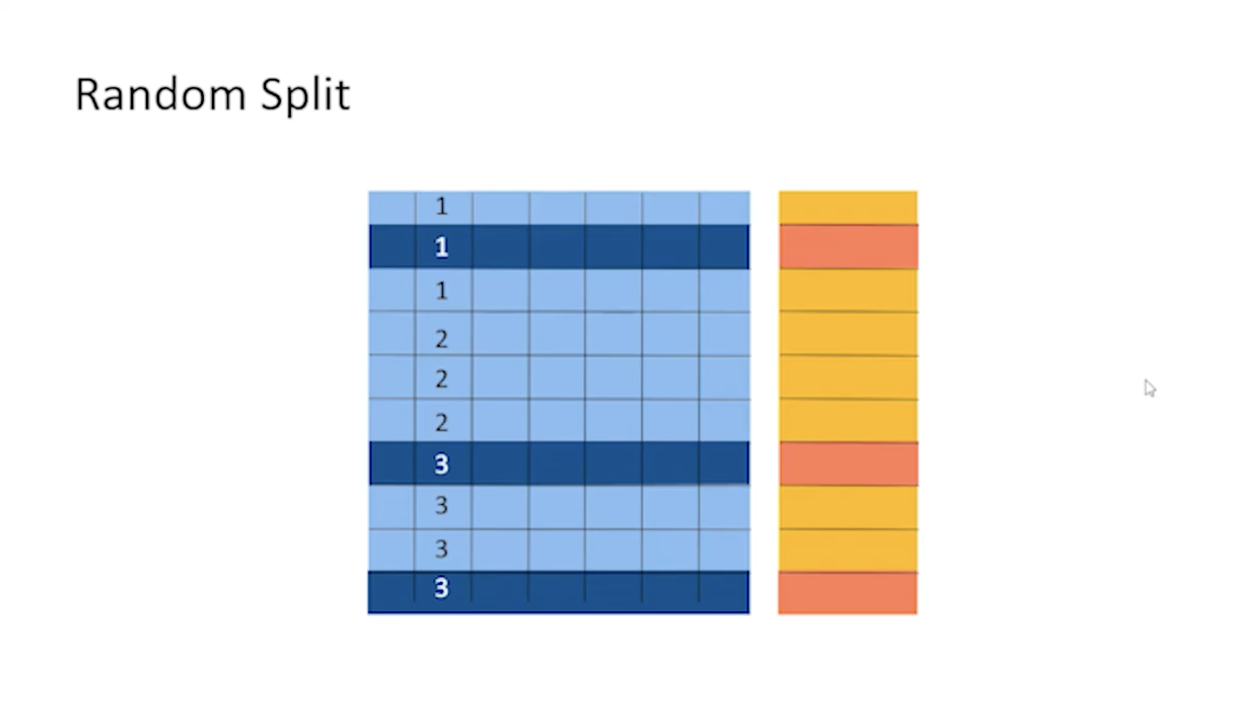
단순히 데이터를 나누는 것뿐만 아니라, 데이터를 나눌 때 어떻게 나눌지도 방법이 존재한다.
위 사진과 같이 데이터는 어떤 컬러를 기준으로 순차 정렬이 되어있는 경우가 많다. 데이터가 순차적으로 정렬이 되어있다고 가정할 때 그냥 위에서부터 70~80%를 자르게 된다면 위쪽에는 3에 대한 정보가 없는 상태에서 학습을 진행하게 될 수도 있다. 그렇기 때문에 다음과 데이터를 랜덤하게 뽑게 된다.
- Overfitting
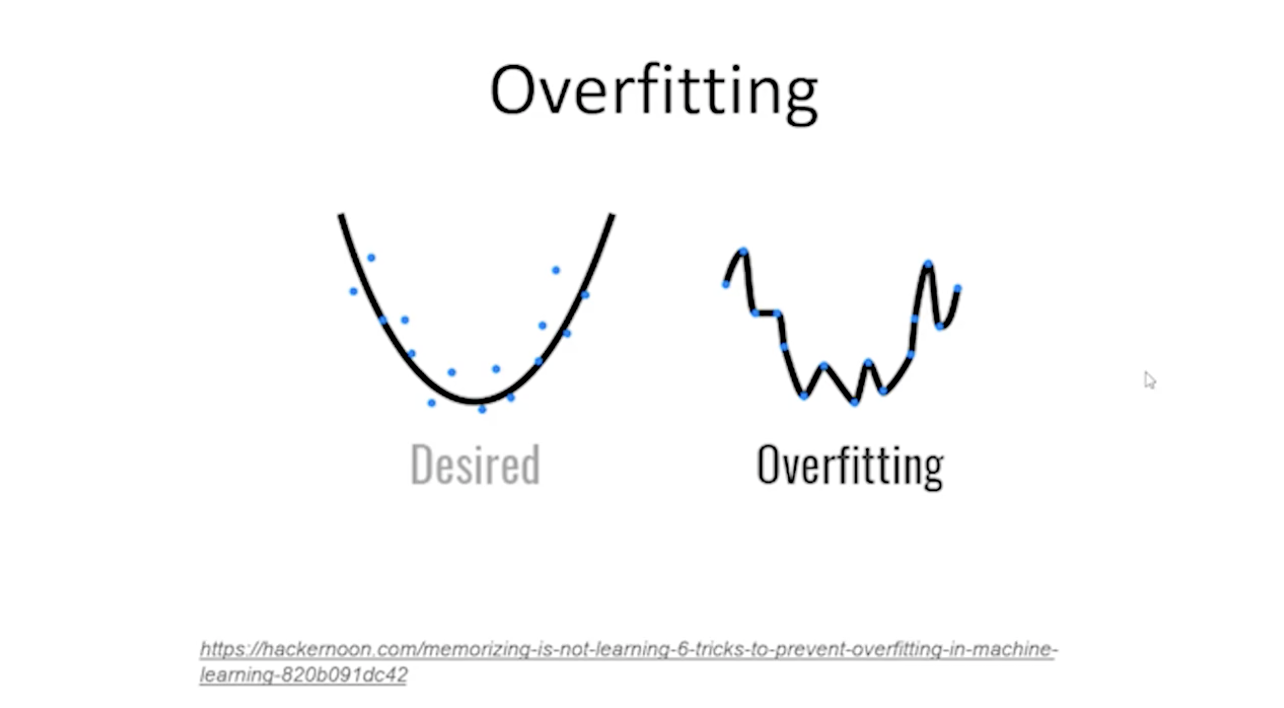
머신러닝 딥러닝을 하다 보면 오버피팅이 일어나는 경우가 굉장히 많다.
오버피팅이란 데이터를 파란색 점으로 가지고 있다고 했을 때 원하는 모델은 Desired와 같이 어느 데이터에나 잘 맞는 일반적인 모델이 아닌 가지고 있는 데이터들에 너무 치중돼서 학습을 하다 보면 우측과 같이 오버피팅이 일어나게 된다.
즉, 자연스럽게 모델이 만들어지지 않고 그래프가 주어진 데이터에 너무 최적화되기 위해서 이상하게 꺾이는 경우를 바로 오버피팅이라고 한다.
- Overfitting 문제점
오버피팅이 된 모델은 훈련 데이터들에 대해서는 100%의 정확도를 가질 것이다. 하지만 가지고 있지 않은 다른 데이터를 넣었을 때 y값이 제대로 나올 수 없다.
- Overfitting 회피 방법
- 데이터를 많이 준비
- 데이터가 적을 경우 Data Augmentation 작업 수행
- 알고리즘 중 오버피팅이 상대적으로 적은 알고리즘을 선택하여 학습 진행
- Regularization(규제화) 값 추가
- Dropout 값 추가
데이터가 적은 경우 오버피팅이 많이 일어나게 된다. 즉 데이터를 많이 준비하며 데이터가 충분히 많지 않은 경우에는 Data Augmentation이라는 데이터를 부풀리는 작업을 할 수 있다(이미지 같은 경우에 많이 사용).
또 학습 알고리즘 중 오버피팅이 상대적으로 일어나지 않는 알고리즘을 선택하여 학습을 시킬 수 있다. 그 외에 Regularization이라고 해서 규제화 라는 값을 추가할 수 있고, Dropout을 추가하는 방법이 있다.
MachineLearning Workflow

머신러닝을 활용할 때 어떤 문제를 풀기 위해서 머신러닝을 하려고 하는지 문제 정의를 먼저 해야 한다. 그런 다음에 그 문제를 풀 수 있는 데이터 셋을 준비한다. 그 뒤 훈련 셋과 평가 셋으로 구분하여 데이터 셋을 준비한다. 가끔은 훈련 셋과 평가 셋의 순서가 바뀌는 경우도 존재하는데, 일반적으로는 문제를 정의하고 데이터 셋을 준비한다.
그런 다음 어떤 알고리즘으로 어떤 모델로 데이터를 학습시킬 것인지 모델을 설정한다.
설정한 모델로 준비한 데이터를 학습시키고 평가 데이터로 모델의 평가를 여러번 진행하여 어떤 모델로 만든 것이 가장 좋은 것인지 판단을 내린다.